alembic генерирует пустые миграции
import os
import sys
from logging.config import fileConfig
from setuptools import setup, find_packages
from sqlalchemy import engine_from_config
from sqlalchemy import pool
from alembic import context
sys.path.append(os.path.join(sys.path[0], 'src'))
from core.database import Base, SQLALCHEMY_DATABASE_URL
from core.config import DB_HOST, DB_NAME, DB_PASS, DB_PORT, DB_USER
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
config = context.config
section = config.config_ini_section
config.set_section_option(section, "DB_HOST", DB_HOST)
config.set_section_option(section, "DB_PORT", DB_PORT)
config.set_section_option(section, "DB_USER", DB_USER)
config.set_section_option(section, "DB_NAME", DB_NAME)
config.set_section_option(section, "DB_PASS", DB_PASS)
# Interpret the config file for Python logging.
# This line sets up loggers basically.
if config.config_file_name is not None:
fileConfig(config.config_file_name)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
target_metadata = Base.metadata
# other values from the config, defined by the needs of env.py,
# can be acquired:
# my_important_option = config.get_main_option("my_important_option")
# ... etc.
def run_migrations_offline() -> None:
"""Run migrations in 'offline' mode.
This configures the context with just a URL
and not an Engine, though an Engine is acceptable
here as well. By skipping the Engine creation
we don't even need a DBAPI to be available.
Calls to context.execute() here emit the given string to the
script output.
"""
# url = config.get_main_option("sqlalchemy.url")
url = SQLALCHEMY_DATABASE_URL
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online() -> None:
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
# configuration = config.get_section(config.config_ini_section)
# configuration['sqlalchemy.url'] = SQLALCHEMY_DATABASE_URL
# connectable = engine_from_config(
# configuration,
# prefix="sqlalchemy.",
# poolclass=pool.NullPool,
# )
# configuration = config.get_section(config.config_ini_section)
# configuration['sqlalchemy.url'] = SQLALCHEMY_DATABASE_URL
connectable = engine_from_config(
config.get_section(config.config_ini_section),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(
connection=connection, target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
Вот файл env.py
И вот файл alembic.ini
# A generic, single database configuration.
[alembic]
# path to migration scripts
script_location = migrations
include_schemas = True
compare_type = True
# template used to generate migration files
# file_template = %%(rev)s_%%(slug)s
file_template = %%(year)d-%%(month).2d-%%(day).2d_%%(slug)s
# sys.path path, will be prepended to sys.path if present.
# defaults to the current working directory.
prepend_sys_path = .
# timezone to use when rendering the date within the migration file
# as well as the filename.
# If specified, requires the python-dateutil library that can be
# installed by adding `alembic[tz]` to the pip requirements
# string value is passed to dateutil.tz.gettz()
# leave blank for localtime
# timezone =
# max length of characters to apply to the
# "slug" field
# truncate_slug_length = 40
# set to 'true' to run the environment during
# the 'revision' command, regardless of autogenerate
# revision_environment = false
# set to 'true' to allow .pyc and .pyo files without
# a source .py file to be detected as revisions in the
# versions/ directory
# sourceless = false
# version location specification; This defaults
# to migrations/versions. When using multiple version
# directories, initial revisions must be specified with --version-path.
# The path separator used here should be the separator specified by "version_path_separator"
# version_locations = %(here)s/bar:%(here)s/bat:migrations/versions
# version path separator; As mentioned above, this is the character used to split
# version_locations. Valid values are:
#
# version_path_separator = :
# version_path_separator = ;
# version_path_separator = space
version_path_separator = os # default: use os.pathsep
# the output encoding used when revision files
# are written from script.py.mako
# output_encoding = utf-8
# sqlalchemy.url = driver://user:pass@localhost/dbname
sqlalchemy.url = postgresql://%(DB_USER)s:%(DB_PASS)s@%(DB_HOST)s:%(DB_PORT)s/%(DB_NAME)s
[post_write_hooks]
# post_write_hooks defines scripts or Python functions that are run
# on newly generated revision scripts. See the documentation for further
# detail and examples
# format using "black" - use the console_scripts runner, against the "black" entrypoint
# hooks = black
# black.type = console_scripts
# black.entrypoint = black
# black.options = -l 79 REVISION_SCRIPT_FILENAME
# Logging configuration
[loggers]
keys = root,sqlalchemy,alembic
[handlers]
keys = console
[formatters]
keys = generic
[logger_root]
level = WARN
handlers = console
qualname =
[logger_sqlalchemy]
level = WARN
handlers =
qualname = sqlalchemy.engine
[logger_alembic]
level = INFO
handlers =
qualname = alembic
[handler_console]
class = StreamHandler
args = (sys.stderr,)
level = NOTSET
formatter = generic
[formatter_generic]
format = %(levelname)-5.5s [%(name)s] %(message)s
datefmt = %H:%M:%S
https://github.com/efir-it/store-v2.git - вот репозиторий
Я использовал декларативный подход sqlalchey к написанию объектов бд, т к считается современном, но при таком подходе при создании модели не передается maradata. В других репозиториях видел в target_matadata просто передает Base.metadata. Я сделал также но нечего не поменялось, так же читал что надо включить параметры
include_schemas = True
compare_type = True
Для создания миграций я использовал команду alembic revision --autogenerate -m "create db" и после alembic revision --autogenerate -m "create db"
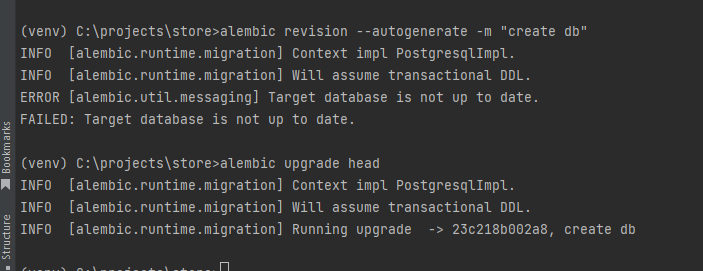
Но тоже безрезультатно, подскажите пожалуйста, что я делаю не так

 Простой
Простой
 Простой
Простой
 Простой
Простой