Создаю нейронную сеть. Обучение с подкреплением. Reinforcement learning.
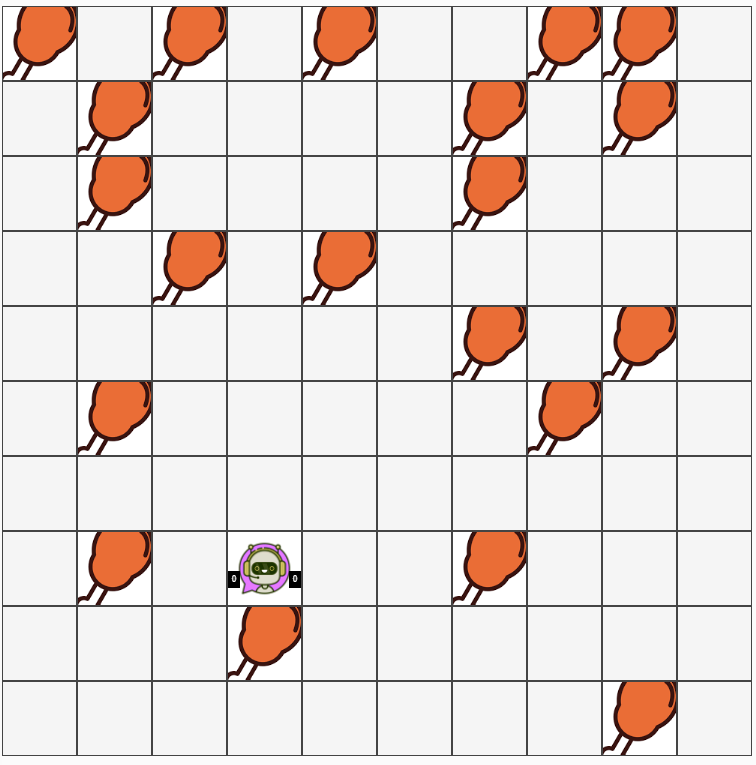
Агент двигается по полю 10х10. Его задача - собрать как можно больше куриных ножек.
Изначально пробовал генетический алгоритм, он показал максимальный результат = 10 шт (на доске всего 20).
Сейчас решил попробовать метод наград и штрафов. Но возникла проблема с кодом.
Награды: за попадание на клетку с куриной ножкой, за каждый ход (чтобы дольше оставался в игре)
Штрафы: выход за границы, шаги туда-сюда, превышение максимального кол-ва ходов
Модель системы - 63 входа (состояние среды) - 23 нейрона в скрытом слое - 4 нейрона на выходе ( [0,0,0,1] - где содержатся вероятности хода наверх, вниз, вправо, влево )
Заполнил сеть рандомными весами. Нейросеть предсказывает каждый ход боту.
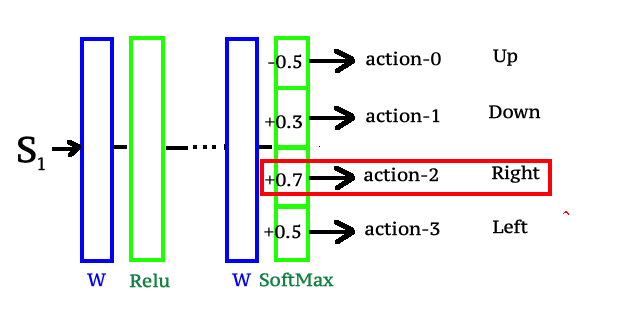
Использую tensorflow js. Хочу чтобы на каждом новом шагу веса корректировались в зависимости от наград и штрафов. Чтобы за границы не выходил, а понимал, что нужно исследовать окружение.
Если бот сходил вправо и вышел за границы игрового поля - начисляю ему штраф, это должно быть плохим примером для нейронной сети. Далее беру выходной нейрон, который показывал наибольшую вероятность (ход вправо) и каким-то образом делаю обратное распространение...уменьшаю веса градиентом по всей цепочке от
этого одного выходного нейрона до входных данных.
Кто-нибудь знает как это выглядит в коде tensorflow?
В итоге хочется получить что-то по типу
tf.model.namefunction( нейрон выходного слоя, x )
где x - значение на которое сделать обратное распространение. За штраф скажем -0.01, за награду 0.004

 Простой
Простой
