Хотел спарсить
https://transparencyreport.google.com/safe-browsin..., сервис через который можно проверить домен или ссылку на бан от гугла,
но чтобы я не делал, я получал вывод "[]", даже user-agent добавил, думая, что сделал что-то не то, но когда я просто вывел весь код через этот же скрипт, я получил совсем другой код, не тот, что был при обычном инспектировании, открыв исходный код в браузере я понял почему,
проще говоря через инспект одно, через исходный код другое
import requests
from bs4 import BeautifulSoup
url = 'https://transparencyreport.google.com/safe-browsing/search?url=discord-free.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0'
}
page = requests.get(url, headers = headers)
soup = BeautifulSoup(page.text, "html.parser")
data = soup.findAll(class_='material-icons ng-star-inserted')
print(data)
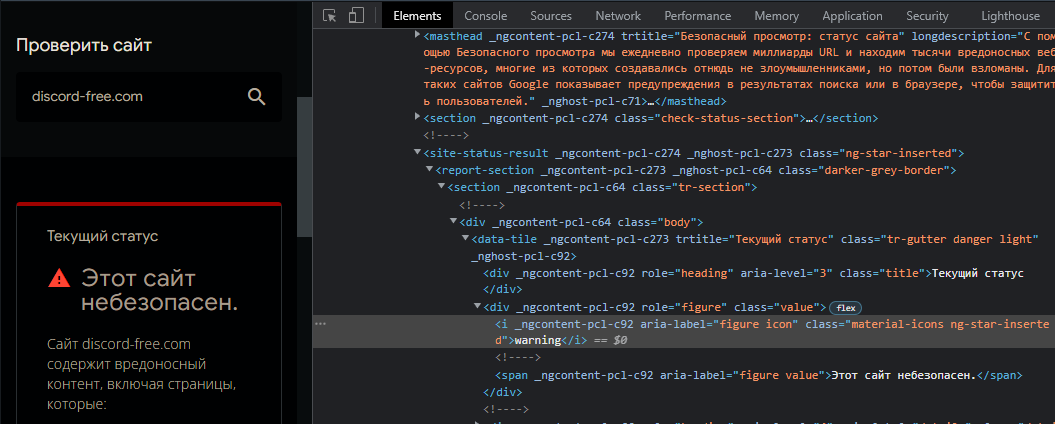
Выше инспектирование где всё есть

Ниже исходный, именно его скрипт читает и ничего не находит
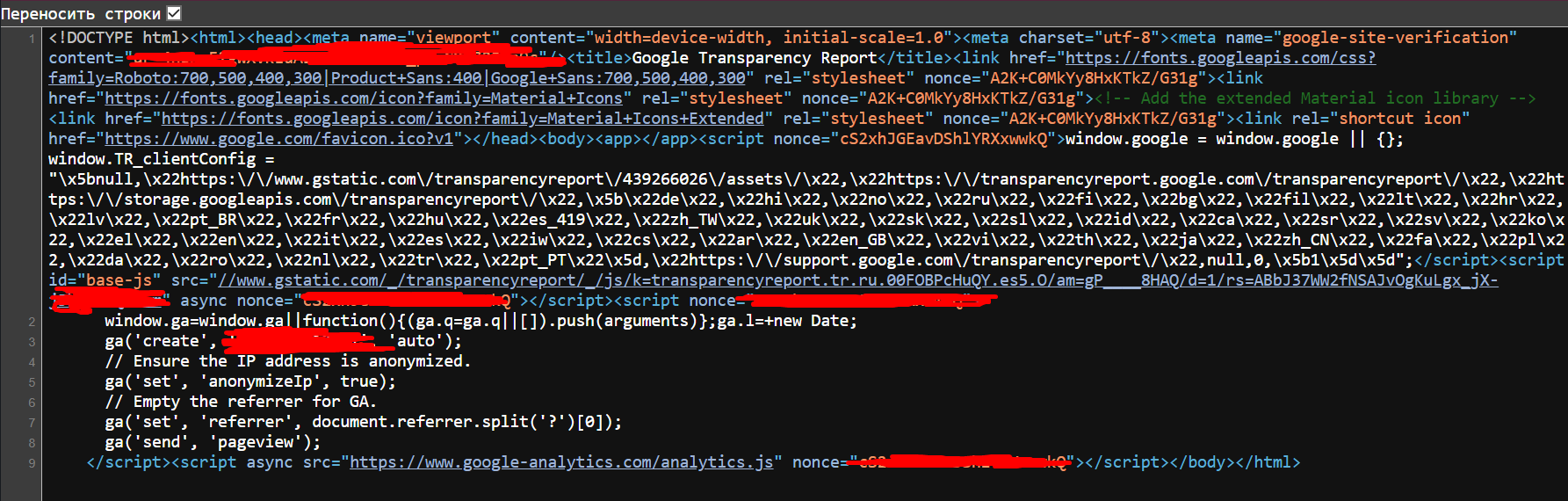
Можно ли как-то спарсить это?
За ранее спасибо!




