def price_parse(links):
import requests
from lxml import etree
for url in links:
info = requests.get(url)
tree = etree.parse(info, etree.HTMLParser())
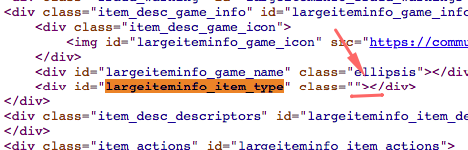
rarity = tree.xpath('.//*[@id="largeiteminfo_item_type"]')[0].text
print(rarity, url)def price_parse(links):
import requests
from bs4 import BeautifulSoup
for url in links:
info = requests.get(url)
soup = BeautifulSoup(info.content, 'html.parser')
rarity = soup.find('div', id='largeiteminfo_item_type')
print(rarity, url)<div id="largeiteminfo_item_type" class>Covert Pistol</div>
import io
import requests
from lxml import etree
for url in links:
info = requests.get(url)
tree = etree.parse(io.StringIO(info.text), etree.HTMLParser())
rarity = tree.xpath('.//*[@id="largeiteminfo_item_type"]')[0].text
print(rarity, url)