(я возможно не правильно задал вопрос, прошу отвечать без жесткой критики в мой адрес)
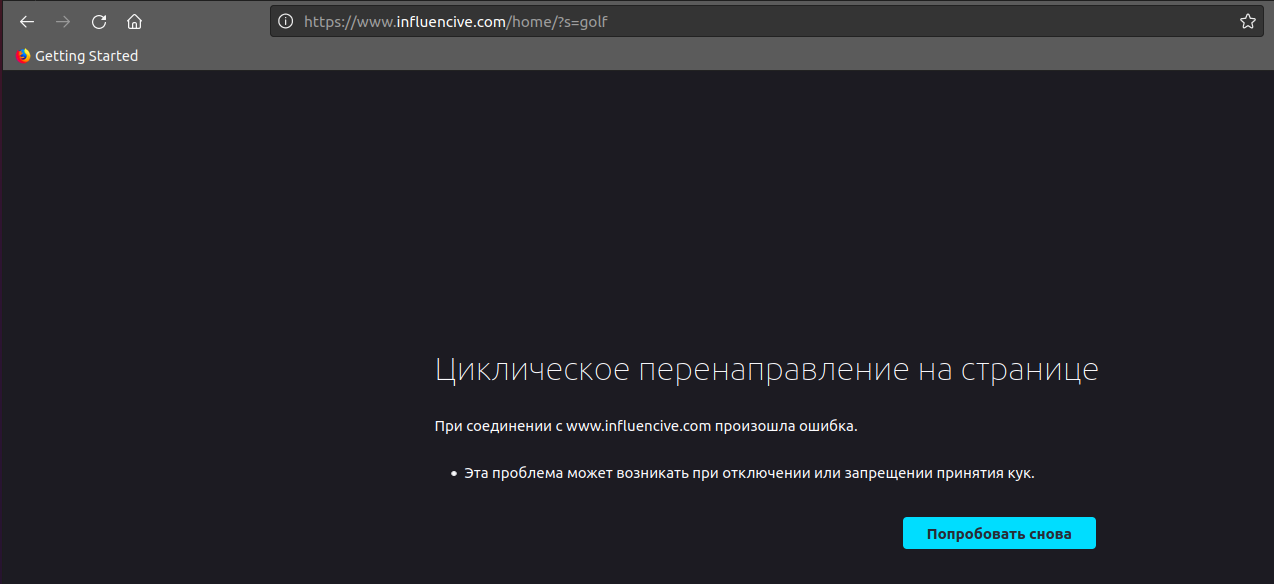
Когда процесс "парсинга" переходит на несуществующий адрес, например к
https://www.influencive.com/page/10/?s=golf , Программа "думает" 10 секунд, после чего крашится.
Консоль:
...
One Thing Superstar Athletes Do That Can Help You Lose Weight—It’s Not What You Think
Daniel Thomas Hind
How Inbound Marketing Helped These 7 Saas Startups Grow
Kevin Payne
Traceback (most recent call last):
File "test.py", line 13, in <module>
r = requests.get("https://www.influencive.com/page/" + str(page) + "/?s=" + search, headers=header)
File "/home/dima/.local/share/virtualenvs/Social_info-HrrlgGsp/lib/python3.8/site-packages/requests/api.py", line 75, in get
return request('get', url, params=params, **kwargs)
File "/home/dima/.local/share/virtualenvs/Social_info-HrrlgGsp/lib/python3.8/site-packages/requests/api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
File "/home/dima/.local/share/virtualenvs/Social_info-HrrlgGsp/lib/python3.8/site-packages/requests/sessions.py", line 542, in request
resp = self.send(prep, **send_kwargs)
File "/home/dima/.local/share/virtualenvs/Social_info-HrrlgGsp/lib/python3.8/site-packages/requests/sessions.py", line 677, in send
history = [resp for resp in gen]
File "/home/dima/.local/share/virtualenvs/Social_info-HrrlgGsp/lib/python3.8/site-packages/requests/sessions.py", line 677, in <listcomp>
history = [resp for resp in gen]
File "/home/dima/.local/share/virtualenvs/Social_info-HrrlgGsp/lib/python3.8/site-packages/requests/sessions.py", line 166, in resolve_redirects
raise TooManyRedirects('Exceeded {} redirects.'.format(self.max_redirects), response=resp)
requests.exceptions.TooManyRedirects: Exceeded 30 redirects.
Сам код
import requests
from bs4 import BeautifulSoup as BS
search = "golf"
page = 1
s = 0
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
while True:
r = requests.get("https://www.influencive.com/page/" + str(page) + "/?s=" + search, headers=header)
html = BS(r.content, "html.parser")
news = html.find_all('a', rel='bookmark' )
name = html.find_all('strong', itemprop = "name" )
if(len(news)):
for s in range(len(news)):
try:
print(news[s].text)
print(name[s].text)
except:
s += 1
page += 1
else:
break

 Средний
Средний
 Сложный
Сложный
