req_header = req.get(url_site, headers=headers)req_header.encoding = req_header.apparent_encoding
j = json.loads(response.text) # Загружаем ответ от requests
html = j['html']['sv-product-tabs-ajax-download'] # Достаем html
soup = BeautifulSoup(html,'lxml')
# Далее все стандартноabout_product_info = soup_detail_info.find('div', class_="ty-product-feature__label")-не работает, не может найти нужные элементы.
Полагаю переход идет через сервера почтового ящика (мне так кажется )Кажется.
Но если приходить ссылка для регистрации аккаунта или что то подобное, вытащить её и перейти по ней не дает нужного результата.
https://www.cian.ru/cat.php?deal_type=sale&engine_version=2&offer_type=flat&p=8®ion=1&room1=1&room2=1import requests
import json
html = requests.get('https://xn--80aesfpebagmfblc0a.xn--p1ai/information/').text
start = '<cv-spread-overview :spread-data=' # Начало обрезки
end = "isolation-data" # Конец обрезки
raw_json_data = html[html.find(start)+34:html.find(end)-3] # Вырезаем json из html страницы
json_data= json.loads(raw_json_data)
for item in json_data:
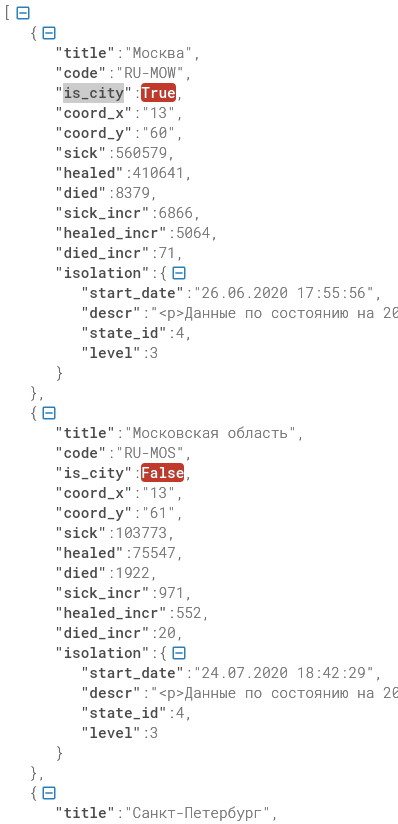
title = item['title'] # Город
sick = item['sick'] # Выявлено
healed = item['healed'] # Выздоровело
died = item['died'] # Умерло
sick_incr = item['sick_incr'] # Новые
healed_incr = item['healed_incr'] #В ыздоровело за сутки
died_incr = item['died_incr'] # Умерло за сутки
print(f'{title} - {sick} - {healed} - {died} - {sick_incr} - {healed_incr} - {died_incr}')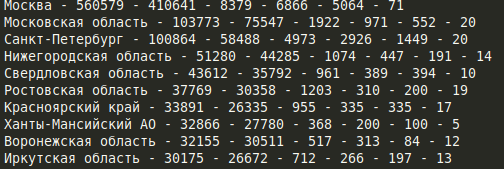

from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("user-data-dir=/home/sergey/SeleniumProfile")
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://google.com")
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("user-data-dir=C:\\profile")
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://google.com")
get_text().replace(',','').text().replace(',','')
import requests
import json
import requests
headers = {
'content-type': 'application/json',
}
data = '''{"filter":{"rated":"Any",
"orderBy":"WithRates",
"tag":"",
"reviewObjectId":276,
"reviewObjectType":"banks",
"page":"1",
"pageSize":20,
"locationRoute":"",
"regionId":"",
"logoTypeUrl":"banks"
}}'''
response = requests.post('https://www.sravni.ru/provider/reviews/list',data=data,headers=headers)
reviews = json.loads(response.text)
total = reviews['total']
print(f'Всего отзывов: {total}')
for review in reviews['items']:
title = review['title']
text = review['text']
print(f'{title} - {text}')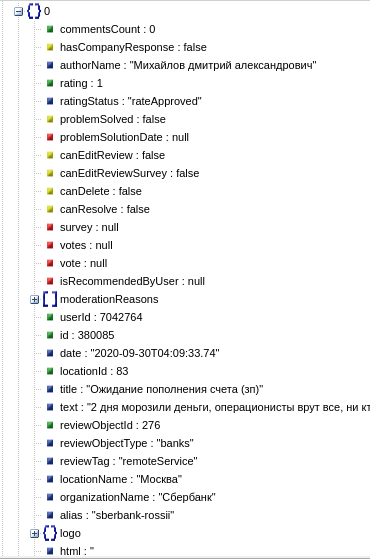
import requests
from bs4 import BeautifulSoup
from lxml import html
import os
def parsing(filename):
with open(filename) as file:
data = file.read()
soup = BeautifulSoup(data,"html.parser")
title = soup.find('h1',class_='question__title').text.strip()
print(title)
os.chdir('html')
fileList = os.listdir('./')
for file in fileList:
parsing(f)