from pywebhdfs.webhdfs import PyWebHdfsClient
from pprint import pprint
hdfs = PyWebHdfsClient(host='hadoop01',port='50070', user_name='hadoop') # your Namenode IP & username here
my_dir = '/examples/Reutov_mos_obl.csv'
pprint(hdfs.list_dir(my_dir))nano /app/hadoop/etc/hadoop/hadoop-env.sh# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}
# export JAVA_HOME=/opt/jdk1.8.0_144
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
export HADOOP_CONF_DIR=/app/hadoop/etc/hadoop/hadoop-daemon.sh --config /app/hadoop/etc/hadoop --script hdfs start namenode
hadoop-daemon.sh --config /app/hadoop/etc/hadoop --script hdfs start datanode
/app/hadoop/sbin/start-dfs.sh
yarn-daemon.sh --config /app/hadoop/etc/hadoop start resourcemanager
yarn-daemon.sh --config /app/hadoop/etc/hadoop start nodemanager
yarn-daemon.sh --config /app/hadoop/etc/hadoop start proxyserver
/app/hadoop/sbin/start-yarn.sh
mr-jobhistory-daemon.sh --config /app/hadoop/etc/hadoop start historyserver[hadoop@hadoop01 ~]$ jps
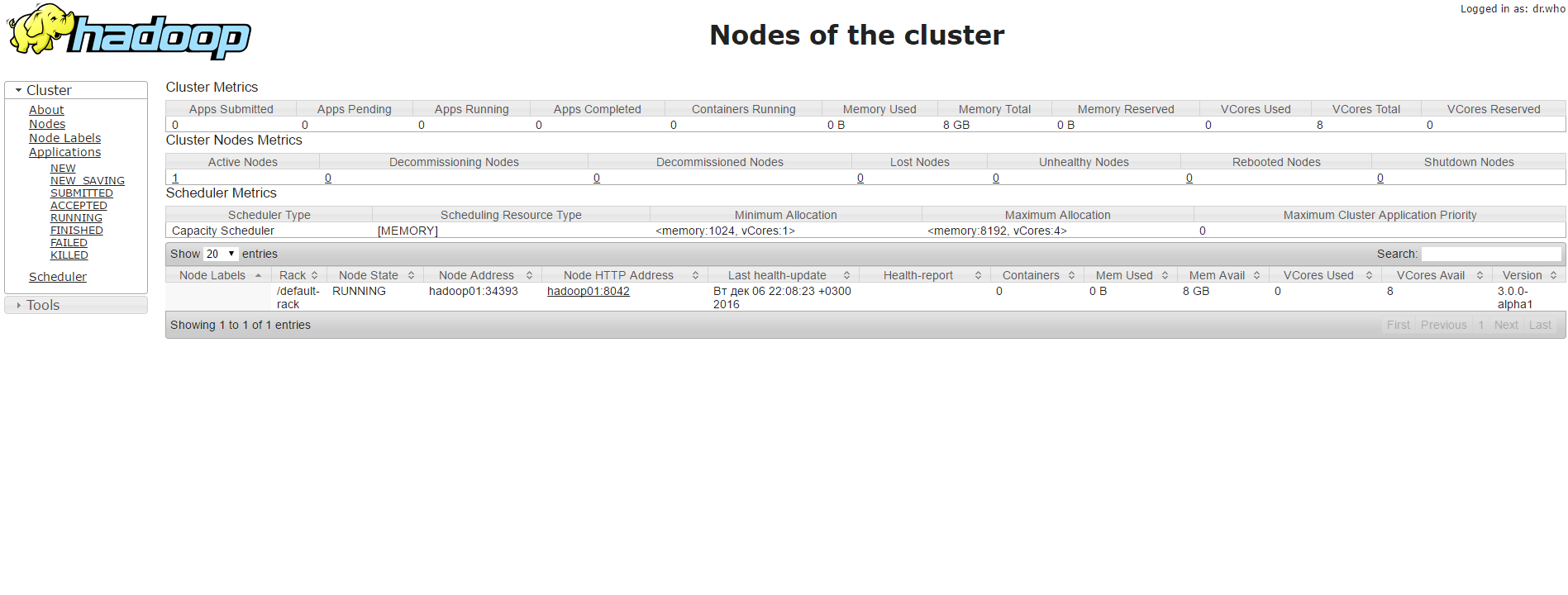
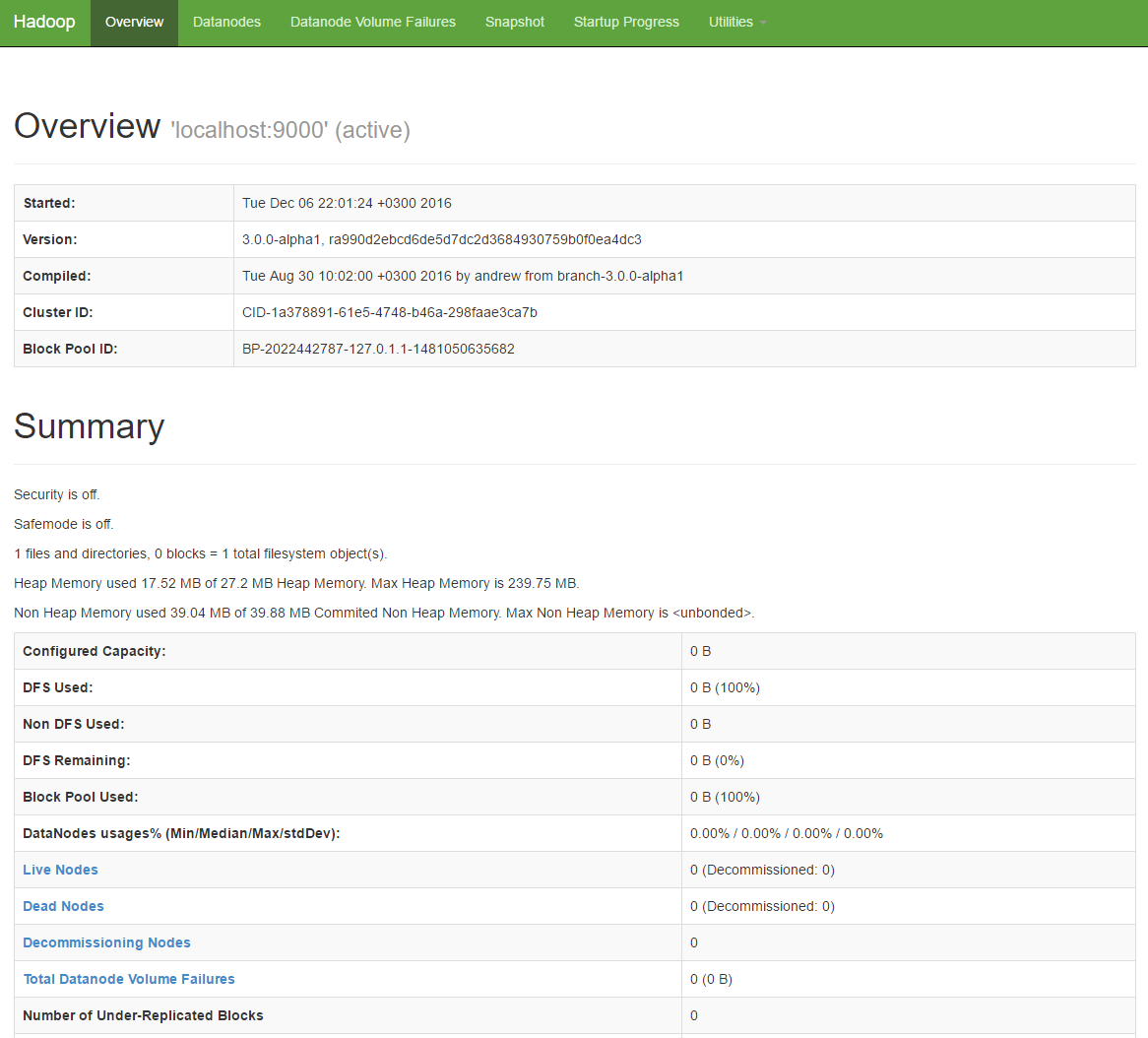
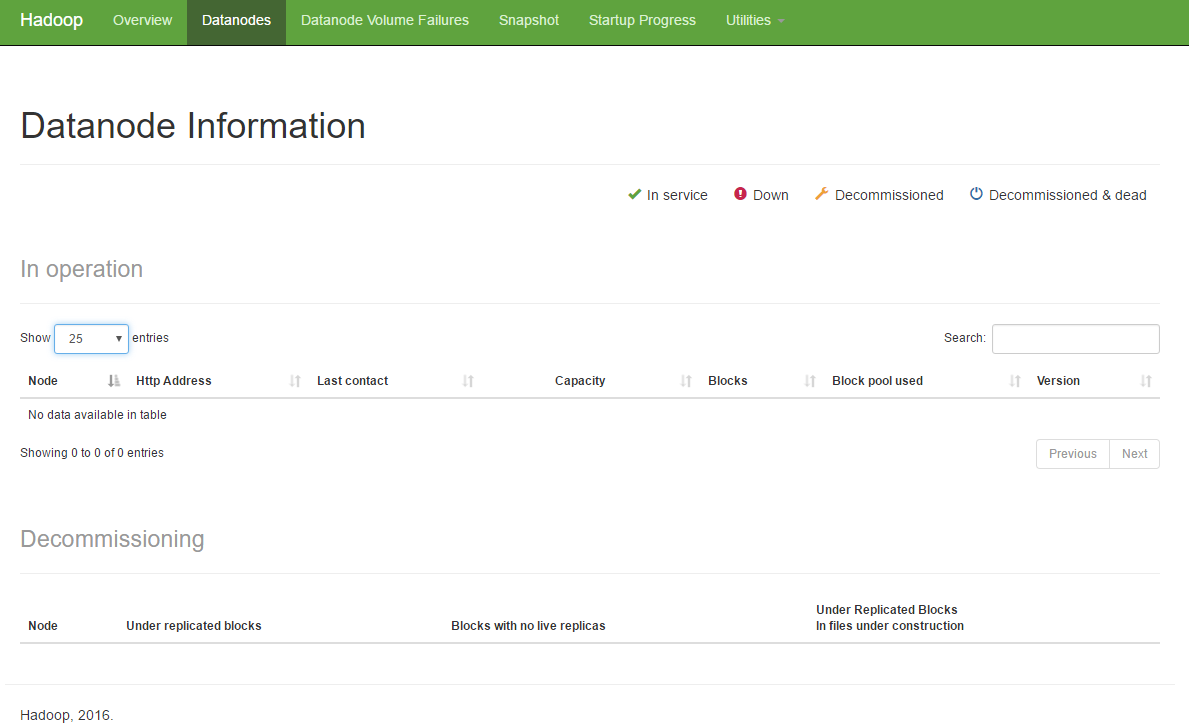
29520 JobHistoryServer
29249 NodeManager
28467 NameNode
29000 ResourceManager
28555 DataNode
29933 Jps
28862 SecondaryNameNode