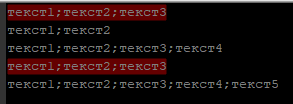
Главное, чтобы было четыре секции между двоеточиями.
Если это главное (и единственное) требование, то сами секции задаются как раз этим двоеточием. Поэтому банальное (но пока что ошибочное) рег. выражение:
.*:.*:.*:.*
Двоеточие в этом выражении соответствует двоеточию в исходной строке. Поэтому строка
a:b:c будет не валидной - слишком мало секций. Выражение
.* означает любое количество любых символов. Ошибка здесь в том, что любым символом также может быть двоеточие, поэтому это регулярное выражение разрешает более, чем 4 секции. Чтобы исправить это, нужно запретить символ двоеточия в последовательности любых символов. Выражение
[^:] означает любой символ, кроме двоеточия:
[^:]*:[^:]*:[^:]*:[^:]*
Остался последний штрих. Пока что это рег. выражение всё ещё разрешает более одной секции, потому что поиск можно начинать с середины строки и заканчивать, не доходя до конца. Поэтому если подсунуть строку
a:b:c:d:e:f выражение убедится, что подстрока
a:b:c:d соответствует рег. выражению, а значит валидна. Чтобы исправить это, нужно указать, что проверку нужно начинать с самого начала строки и дойти до самого конца строки. То есть рассматривать строку целиком, а не по частям. Это делается с помощью указателей позиций. Символ
^ (в начале) означает начало строки, а символ
$ (в конце) означает конец строки:
^[^:]*:[^:]*:[^:]*:[^:]*$
Собственно,
это и есть правильный ответ в общем виде на вопрос с главным требованием. Секции ровно четыре и они разделены двоеточием. В каждой секции двоеточие запрещено. Выражение
[^:]* означает любое количество любых символов, кроме двоеточия, что нам и нужно.
Однако данное выражение можно немного улучшить, в зависимости от дополнительных требований. Например, нас может не устроить, что для каждой секции считается валидным любое количество символов, даже нулевое. То есть строка
a:b::c тоже будет валидной. Для этого нужно сменить квантификатор
* на какой-либо другой. Например, можно сменить на
+, который означает любое количество вхождений (символа) больше нуля, то есть 1 и более:
^[^:]+:[^:]+:[^:]+:[^:]+$
Далее, может быть желательно выделить группы, чтобы рег. выражение не только проверяло исходную строку на соответствие шаблону
ip:port:user:pass, но и извлекало эти самые переменные. Группы задаются просто скобками. Очевидно, что разделители и указатели позиций в группы не входят:
^([^:]+):([^:]+):([^:]+):([^:]+)$
Далее можно вспомнить, что параметр
port может содержать лишь арабские цифры. В регулярных выражениях
\d (или
[0-9]) означает любую цифру. Так что легко вносим улучшение:
^([^:]+):(\d+):([^:]+):([^:]+)$
Хотя постойте-ка. Это ещё не всё с параметром
port. Ведь абсолютное любое число, состоящее из цифр, нас не устроит. Как минимум, порт не может быть больше 65535, поэтому любое число выше считается ошибкой. В принципе, на данном этапе можно не заморачиваться и просто проигнорировать это требование, а реально проверить его позже кодом типа такого:
$post < 65356, но в качестве примера можно всё же ограничить количество цифр от 2 до 5:
^([^:]+):(\d{2,5}):([^:]+):([^:]+)$
Квантификатор {2,5} означает, что количество вхождений (цифр) должно быть не менее 2 и не более 5, иначе секция будет считаться не валидной, а значит и вся строка тоже.
Далее, можем также сделать более строгое условие для параметра
ip. Для простоты будем считать, что разрешён только IPv4, а IPv6 нельзя использовать. Тогда условием будет 4 цифры, разделённые точкой. Каждая цифра от 1 до 3 символов:
\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}
Ой, ошибочка вышла! Дело в том, что символ
. является квантификатором. И чтобы рег. выражению сказать, что нам нужен сам символ точки, нужно его экранировать:
\.
В результате полностью рег. выражение получается таким:
^(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}):(\d{2,5}):([^:]+):([^:]+)$
Да, получился монстр. Но нет предела совершенству.
Правда, на этом этапе улучшать проверки уже не целесообразно. Далее уже кодом PHP можно проверить более строги условия. Например, сейчас в качестве
ip будет валидной строка
300.400.500.600. Ведь всё сходится - 4 числа, разделённые точкой, в каждом от 1 до 3 цифр. Поэтому нужно либо более монструозное выражение лепить, либо кодом проверять, либо отдать на откуп сетевым ошибкам подключения - зависит от конкретного приложения и конкретной задачи.
Рег. выражения не заточены на сравнение чисел, например. Чтобы проверить, что число находится в диапазоне от 0 до 255, придётся лепить что-то такое:
(?:\d\d?|[0-1]\d\d|2[0-4]\d|25[0-5])
То есть это вообще поразрядная проверка. Глупо. Проще это делать кодом, если это действительно нужно.
На данном же этапе имеет смысл проверять лишь то, подо что заточены регулярные выражения. Например, можно ограничить класс символов, которые входят в
user и в
pass. Например, в пароле можно разрешить только латинские символы и цифры, а также ограничит длину: пароль не может быть меньше 6 и не может быть больше 32 символов:
[a-z0-9]{6,32}
(просто пример)
И так далее в таком же духе. Как было сказано выше, прочие тонкости уже зависят от конкретной задачи.