Глянул код
Там вложенные таблицы.
//tr/td[1]//a/@href
Мы выбираем все хрэфы из ссылок НЕ СМОТРЯ НА ВЛОЖЕННОСТЬ.
А сама таблица лежит в другой таблице. В первом td.
Те вот эта часть //tr/td[1]
Выбирает не таблицу с данными, а таблицу с таблицей с данными.
А дальше уже ищем там все ссылки (во всей таблице получается)
Ну... навряд browser.find_element_by_xpath будет работать с формами исходя из названия. Скорее это вроде ховера или просто поиска элемента для дальнейшей работы с ним. Поищите у него другие методы. Напр browser.form, browser.input или подобное
Верно лишь отчасти.
Сравнивать можно, но только с пустой строкой.
В новых селекторах есть получение родителей. Правда их не реализовал ещё никто из браузеров https://www.w3.org/TR/selectors-4/#relational
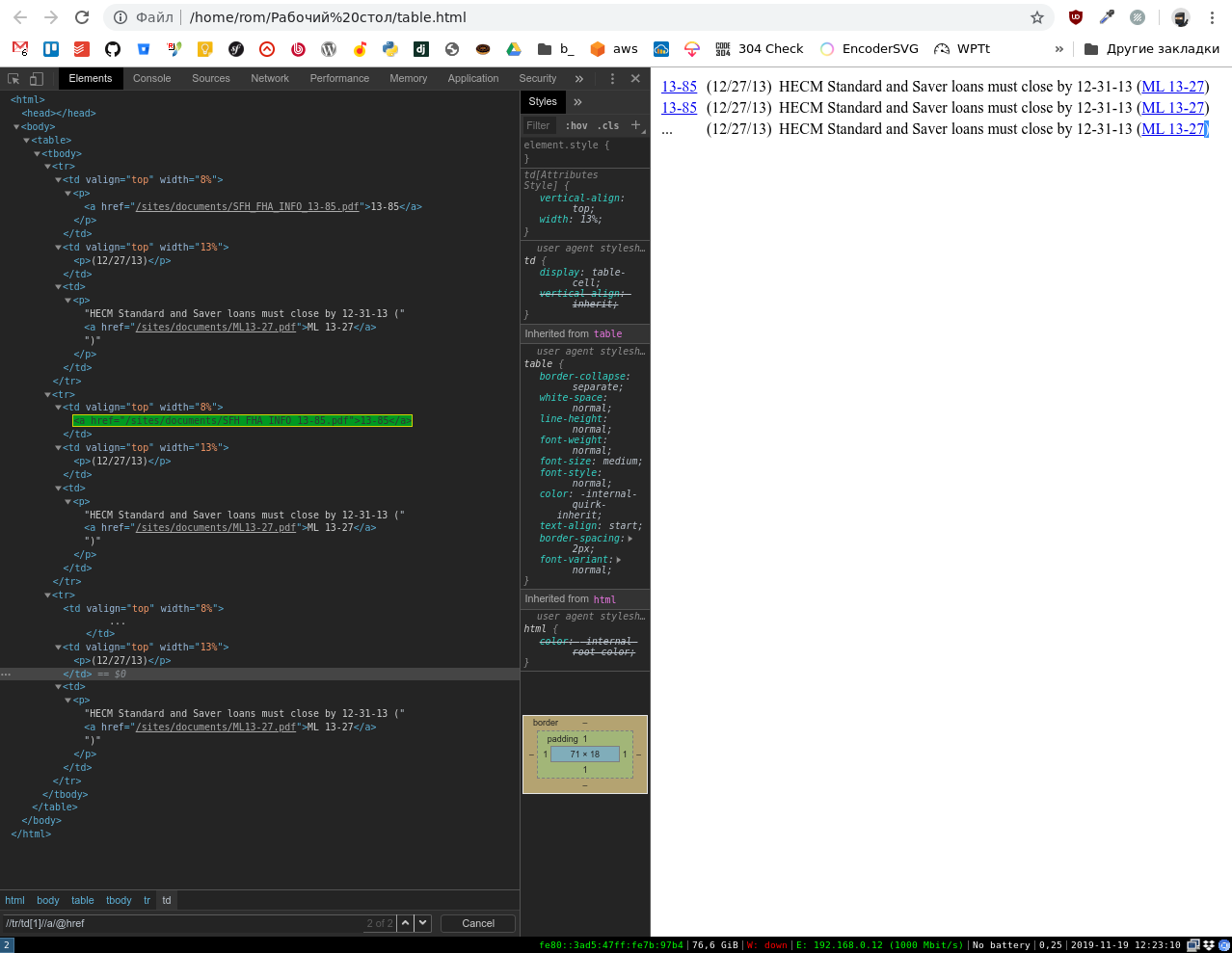
Попробуйте его в инспекторе. У меня находит 7 штук.