Здравствуйте,после препроцессинга картинки у меня имеется такое вот изображение и мне нужно,чтобы его распознавал pytesseract,как это можно сделать?
Вот изображение:
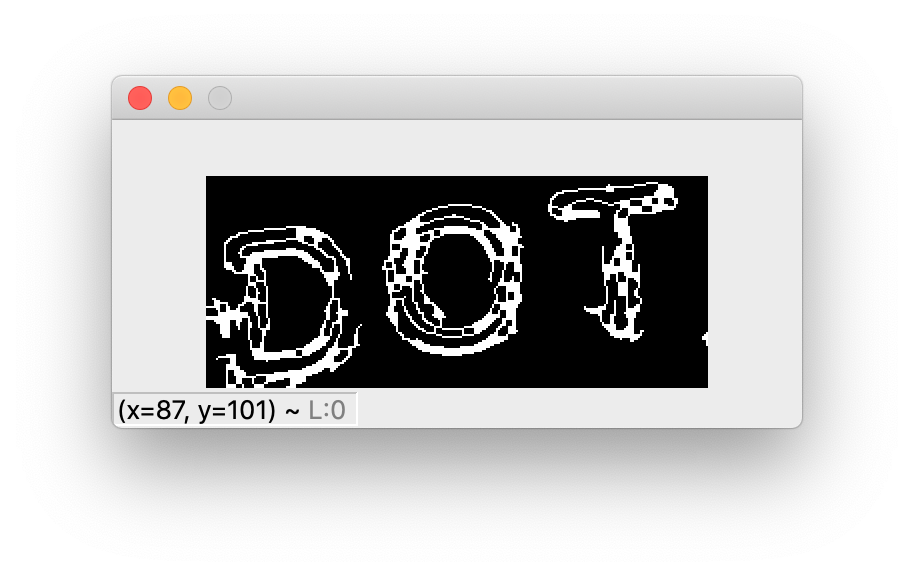
Вот код:
src = cv2.imread('dot.png', cv2.IMREAD_COLOR)
#Transform source image to gray if it is not already
if len(src.shape) != 2:
gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
else:
gray = src
edges = cv2.Canny(gray,50,150)
ret, thresh = cv2.threshold(edges, 127, 255, cv2.THRESH_BINARY)
dilate = cv2.dilate(thresh,kernel,iterations=1)
erode = cv2.erode(dilate,kernel,iterations=1)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
hierarchy = hierarchy[0]
cv2.imshow('',erode)

