
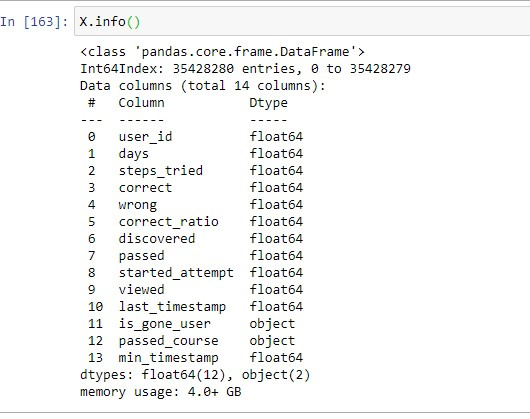

df.memory_usage(deep=True)df['object'].astype('category')
Простой
Простой
Простой
 Простой
Простой
Простой
Простой
