Всем привет!
Есть сайт, с которого нужно извлечь данные фин.отчетности, для примера
вот ссылка
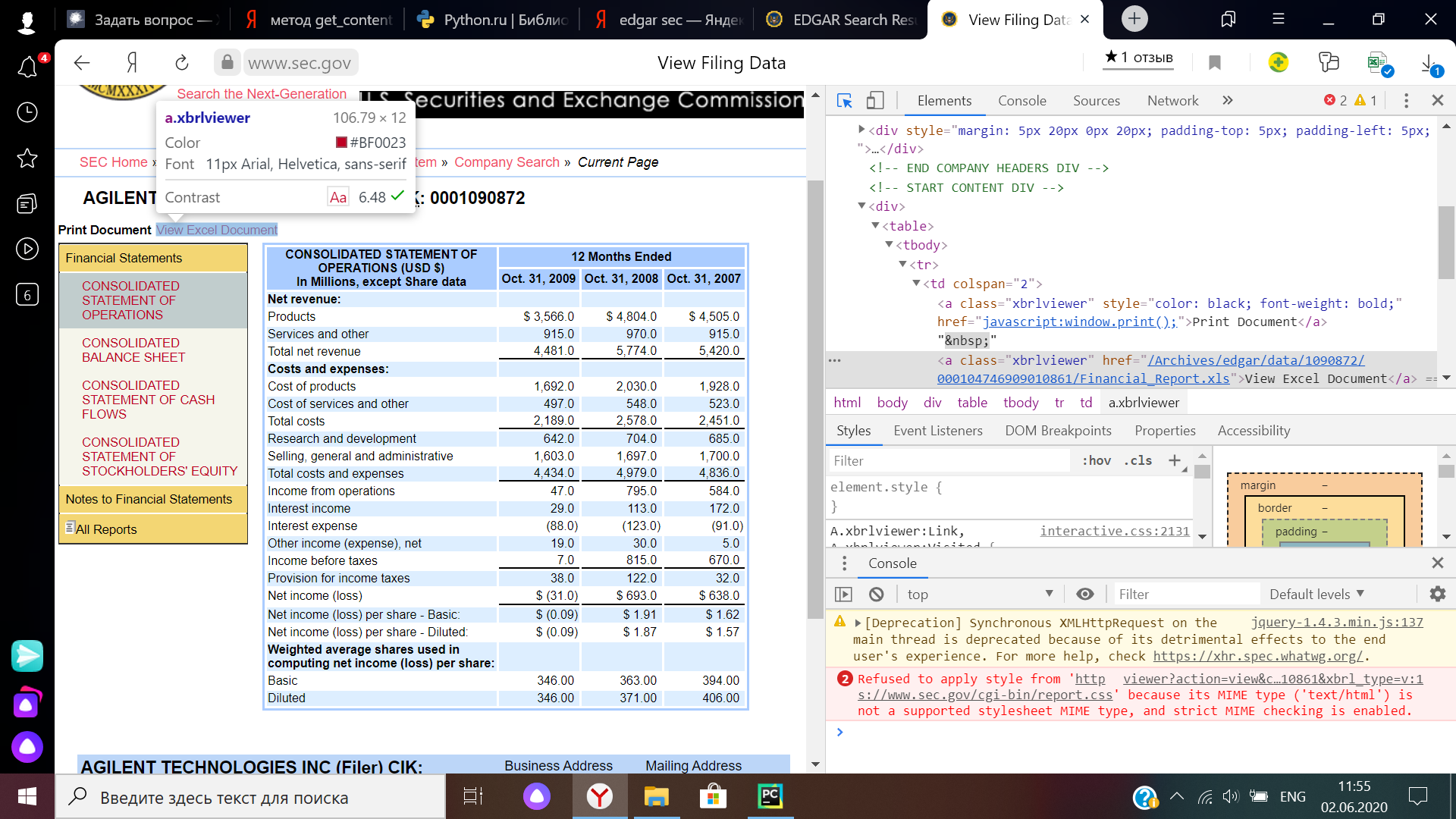
Файлы отчетности в формате Excel скачиваются с этой страницы по кнопке, которая представляет собой ссылку на соответствующую часть файлового архива. Скрин кода страницы и элемента:
Написал код, который формирует нужные ссылки для скачивания и обращается по ним к сайту
import requests
from bs4 import BeautifulSoup
import re
from time import sleep
import urllib.request, urllib.parse, urllib.error
# парсинг на примере Agilent Technologies, Inc.
url = 'https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=A&type=10-K&dateb=&owner=exclude&count=40'
user_agent = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 YaBrowser/20.4.3.257 Yowser/2.5 Yptp/1.23 Safari/537.36'}
res = requests.get(url, headers=user_agent).text
soup = BeautifulSoup(res, 'lxml')
CIK_data = soup.find('span', class_='companyName').find('a').get_text()
CIK_num = re.findall(r'\d+',CIK_data)
CIK = CIK_num[0].lstrip('0')
print('CIK: ',CIK)
Acc_no_data = soup.find_all('tr')[3:]
# print(Acc_no_data)
for elem in Acc_no_data:
sleep(40)
Acc_no = re.findall(r'\d+', elem.find('td', class_='small').text.replace('-',''))[3]
# print(Acc_no)
date = elem.find_all('td')[3].text
get_file = requests.get(f'https://www.sec.gov/Archives/edgar/data/{CIK}/{Acc_no}/Financial_Report.xlsx', headers=user_agent)
И после этого нигде не могу найти файлы, которые по задумке должны быть скачены. Проверил - ссылки формируются корректно, по клику на ссылку файлы качаются в папку "Загрузки".
Умные люди, подскажите - как сделать, чтобы файлы скачивались (и желательно ещё в заранее определенный каталог)? ОС стоит Windows 10.