
def get_link(url):
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser').find('div', class_='task', id='task')
links = []
for i in soup.find_all('a', href=True):
a = i['href']
link = url + a
links.append(link)
return links<div id='media-6' class='media media-6 media-center'></div>
<div class="task"
id="task"
data-host="//gdz-putina.net"
></div>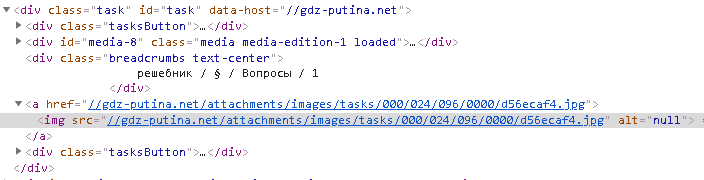 Как мне спарсить ссылку на картинку?
Как мне спарсить ссылку на картинку? 
 Сложный
Средний
Простой
Простой
Сложный
Средний
Простой
Простой