Сайт написан на angular, т.е. в коде страницы только загружаемые скрипты, если парсить через simple_html_dom или что-то подобное, через Curl то просто получаешь список этих скриптов, тело страницы формируется после загрузки скриптов, но ни file_get_content, ни Curl этого не видят. Как спарсить подобный сайт? На ум приходит только headless chrome, но это достаточно долго, может есть какие-то более простые методы?
Сайт на ангуляре/реакте/вью информацию берет не из воздуха, и парсить надо не сайт, а то откуда он эту информацию берет.
В 99% случаев это запросы к API сайта.
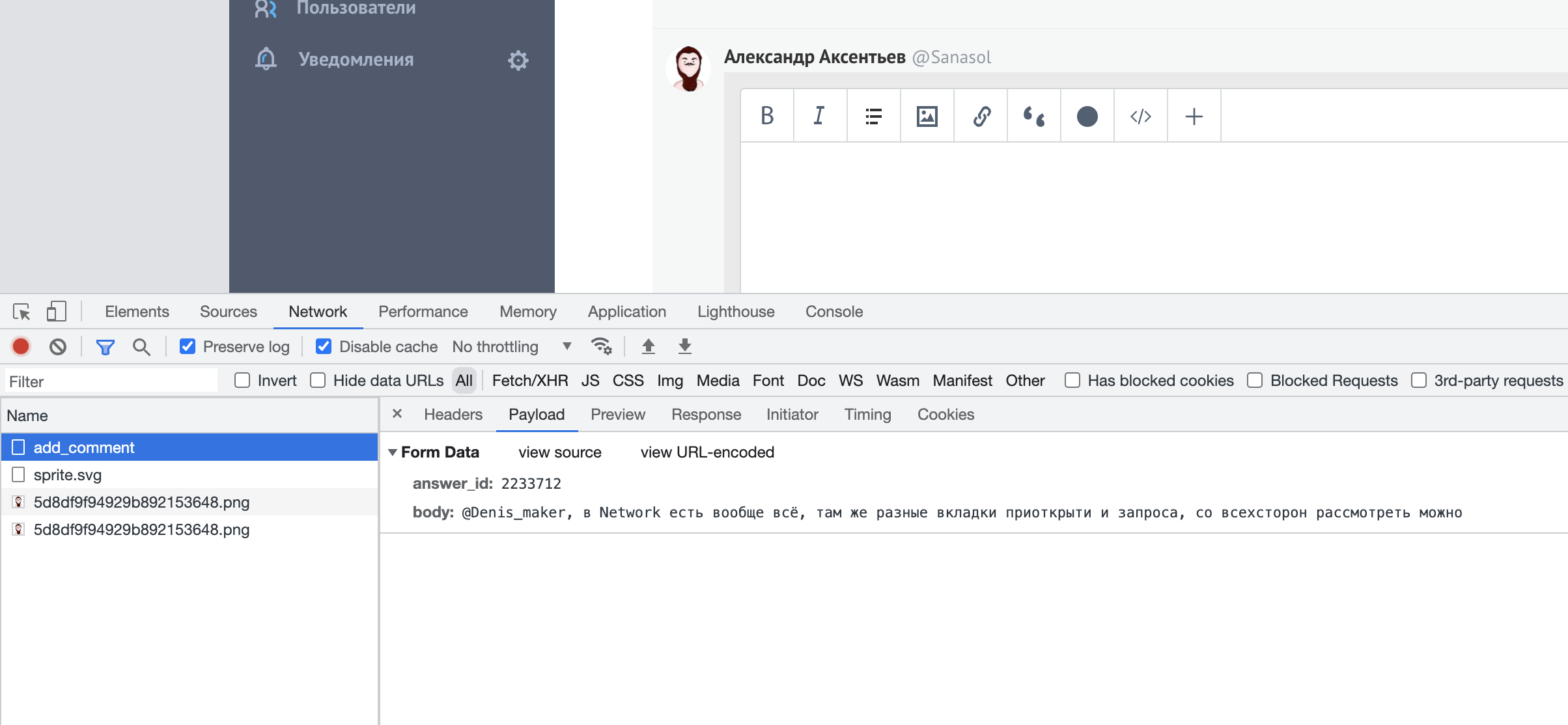
Т.е. надо открывать в DevTools вкладку Network при загрузке и посмотреть по каким ссылкам берутся данные.
А есть способ получить содержимое post запроса? Как узнать, что сайт передаёт на сервер? В Network только ссылка из полезного есть, проверил на примере своего сайта
freeeeez, так скажи чтобы купил вдс, не ему диктовать что использовать, он дал задачу, уведоми его что нужно для выполнения, он примет, вряд-ли он экстрасенс


 Простой
Простой