Я уже много раз сталкивался с проблемой создания нормального Pipeline в sklearn, и в этот раз решил спросить совета здесь. Как сделать полный Pipeline, который на вход получает сырые данные, заполняет пропуски, делит признаки на несколько колонок(Категориальные, вещественные и тд), потом отдельно обрабатывает их и склеивает данные вместе, так чтобы это можно было отдать модели. Мне бы какие-нибудь ссылки на проекты, где это присутствует.
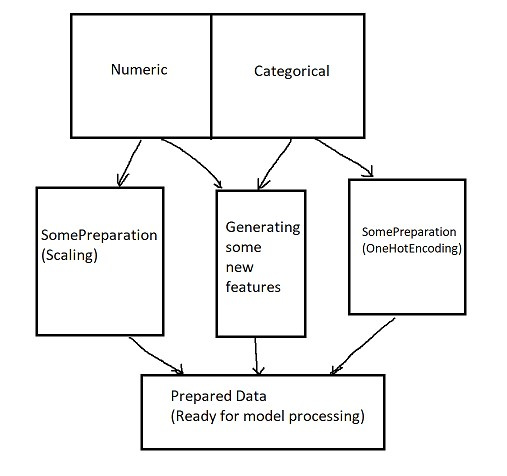
P.S: Обычно во всех туториалах данные обрабатываются в pandas dataframe, а потом уже подаются в модель, а нормальных пайплайнов нет, поэтому я сюда и пишу : )

 Средний
Средний
 Простой
Простой
 Простой
Простой
 Средний
Средний
